In Ethereum consensus mechanism, it’s critical for all participating nodes to agree on the state of the system consistently and efficiently. The Simple Serialize (SSZ) framework facilitates this through Merkleization, a process that transforms serialized data into a Merkle tree structure. This wiki page discusses the intricacies of Merkleization and its importance in ensuring a shared state across nodes in a scalable and secure manner.
Terminology and Methods
- Merkleization: Refers to constructing a Merkle tree and deriving its root.
- Hash Tree Root: A specific application of Merkleization, used to compute the root hash of complex SSZ container.
The Need for Merkleization
Cryptographic hash functions provide a solution by generating a compact, unique representation of a data set for a Beacon state. By hashing the serialized state of a Beacon chain, nodes can quickly and efficiently compare states by exchanging these small hash outputs.
Process of Merkleization
Merkleization involves breaking down the serialized data into 32-byte chunks, which serve as the leaves of a Merkle tree. These chunks are then combined pair-wise, hashed together, and the process is repeated up the tree until a single hash—the Merkle root—is derived. This root hash acts as a unique fingerprint for the entire dataset. The key steps are as below:
- Chunking: Divide the serialized data into 32-byte chunks.
- Tree Construction: Pair up the chunks and hash each pair to form the next level of the tree. Repeat this step until only one hash remains: the Merkle root.
- Padding: If the number of chunks isn’t a power of two, additional zero-value chunks are added to round out the tree, ensuring that the tree is balanced.
Benefits of Merkleization
- Performance Efficiency: While the tree requires hashing approximately twice the original data amount, caching mechanisms can store the roots of subtrees that don’t change often. This significantly reduces the computational overhead as only altered parts of the data need re-hashing.
- Light Client Support: The Merkle tree structure supports the creation of Merkle proofs—small pieces of data that prove the inclusion and integrity of specific parts of the state without needing the entire dataset. This feature is crucial for light clients, which operate with limited resources and rely on these proofs to interact with Ethereum securely.
Merkle Tree Structure and Hashing
The Merkle tree structure is organized such that every two adjacent leaf nodes are hashed together to produce a parent node, and this pairing and hashing continue upwards until a single hash is obtained at the top:
graph TD;
HTR[Hash Tree Root]
HL12[Hash of Leaves 1 and 2]
HL34[Hash of Leaves 3 and 4]
L1[Leaf 1]
L2[Leaf 2]
L3[Leaf 3]
L4[Leaf 4]
HTR --> HL12
HTR --> HL34
HL12 --> L1
HL12 --> L2
HL34 --> L3
HL34 --> L4
Figure: Merkle Tree Structure.
In some instances, the distribution of the leaves might require a more complex tree with varying depths per branch, especially when certain nodes (like containers with multiple elements) need additional depth.
Generalized Indices
To facilitate direct referencing and verification within the tree, each node (both leaves and internals) is assigned a generalized index. This index is derived from the node’s position within the tree:
graph TD;
1((1 / Depth 0))
2((2 / Depth 1))
3((3 / Depth 1))
4((4 / Depth 2))
5((5 / Depth 2))
6((6 / Depth 2))
7((7 / Depth 2))
1 --> 2
1 --> 3
2 --> 4
2 --> 5
3 --> 6
3 --> 7
Figure: Merkle Tree Generalized Indices and Depth Levels.
- Root Index: 1 (depth = 0)
- Subsequent Levels: $2^{depth} + index$ where index is the node’s zero-indexed position at that depth.
Multiproofs Using Generalized Indices
Multiproofs using generalized indices provide an efficient way to verify specific elements within a Merkle tree without needing to know the entire tree structure. This concept is crucial in Ethereum and cryptographic applications where data integrity and verification speed are paramount. Let’s break down the process using an example to understand how multiproofs work:
Understanding the Structure
- A Merkle tree is structured in layers, where each node is either a leaf node (containing actual data) or an internal node (containing hashes of its child nodes).
- Generalized indices numerically represent the position of each node in the tree, calculated as $2^{depth} + index$, starting from the root (index 1).
Tree Layout for the Example
- The tree is structured as follows, with
*indicating the nodes required to generate the proof for the element at index 9:
graph TD;
1(("1*"))---2(("2"));
1---3(("3*"));
2---4(("4"));
2---5(("5*"));
3---6(("6"));
3---7(("7"));
4---8(("8*"));
4---9(("9*"));
5---10(("10"));
5---11(("11"));
6---12(("12"));
6---13(("13"));
7---14(("14"));
7---15(("15"));
classDef root fill:#f96;
classDef proof fill:#bbf;
classDef leaf fill:#faa;
class 1 root;
class 2,5,8,9 proof;
Figure: Merkle Tree Layout
Determining Required Nodes
- Identifying Required Hashes: To validate the data at index 9, you need the hashes of the data at indices 8, 9, 5, 3, and 1.
- Pairwise Hashing: Combine the hashes of indices 8 and 9 to compute the hash corresponding to their parent node, which should be
hash(4). - Further Hash Combinations:
hash(4)is then combined with the hash from index 5 to produce the hash of their parent node,hash(2).- This result is combined with the hash from index 3 to work up to the next level.
- Final Verification: The combined result from the previous step is hashed with the root from the opposite branch (index 3) to produce the ultimate tree root (
hash 1). - Integrity Check: If the calculated root matches the known good root (
hash 1), the data at index 9 is verified as accurate. If the data was incorrect, the resulting root would differ, indicating an error or tampering.
There are helper functions in the consensus specs to calculate the multiproofs and generalized indices. You can find here.
Calculating Hash Tree Roots
The hash tree root of an SSZ object is computed recursively. For basic types and collections of basic types, the data is packed into chunks and directly Merkleized. For composite types like containers, the process involves hashing the tree roots of each component. In the below sections we will see the working examples to understand the process.
Packing and Chunking
Packing and chunking are crucial concepts in the context of Merkleization, especially when dealing with the SSZ used in the Beacon chain. Here’s how packing and chunking work:
Serializing the Data
- Serialization involves converting a data structure (basic types, lists, vectors, or bitlists/bitvectors) into a linear byte array using SSZ serialization rules.
- Each element is serialized based on its type.
Padding the Serialization
- After serialization, the byte array might not perfectly align with the 32-byte chunk size used in Merkle trees.
- Padding is added to the serialized data to extend the last segment to a full 32-byte chunk. This padding consists of zero bytes (0x00).
Dividing into Chunks
- The padded serialized data is then split into multiple 32-byte segments or “chunks.”
- These chunks are the basic units used in the Merkleization process.
Padding to Full Binary Tree
- The number of chunks from the previous step may not be a power of two, which is required to form a balanced binary tree (full binary tree).
- Additional zero chunks (chunks filled entirely with zero bytes) are added as necessary to bring the total count up to the nearest power of two.
- This ensures that the resulting Merkle tree is complete and balanced, facilitating efficient cryptographic operations.
Applying the Merkleization Process
- With the chunks prepared, they are arranged as the leaves of a binary Merkle tree.
- Merkleization proceeds by hashing pairs of chunks together, layer by layer, until a single hash remains. This final hash is known as the Merkle root.
Practical Example: Suppose we have a list of integers that need to be packed and chunked:
- Integers: [10, 20, 30, 40] (Suppose each integer occupies 8 bytes).
- Serialized Data: A continuous byte array created from these integers.
- Padding: If the total serialized length is not a multiple of 32, padding bytes are added.
- Chunks: The data is divided into 32-byte chunks.
- Zero Padding for Tree: If the number of chunks is not a power of two, additional zero-filled chunks are appended.
- Merkleization: The chunks are then used as leaves in a Merkle tree to compute the root.
Mixing in the Length
Mixing in the length is a crucial step in the Merkleization process, particularly when handling lists and vectors. This step ensures that the final hash tree root accurately reflects both the content and the structure of the data, including its length. Let’s break down how this concept is applied and why it’s important.
Purpose of Mixing in the Length
Mixing in the length is used to ensure that two different lists or vectors with similar contents but different lengths generate different hash tree roots. This is critical because without incorporating the length into the hash, two lists—one longer than the other but otherwise identical up to the length of the shorter list—would have the same hash tree root if only the content is hashed. This could lead to potential security vulnerabilities and inconsistencies within the data validation process.
An example of Mixing in the Length
The example below illustrates that without including the length of the list, the Merkle root hashes for a_root_hash and b_root_hash remain the same despite representing two lists of different lengths. However, when the length is incorporated, the Merkle root hash a_mix_len_root_hash differs from both a_root_hash and b_root_hash. This distinction is crucial when dealing with lists or vectors of varying lengths in the merkleization.
>>> from eth2spec.utils.ssz.ssz_typing import uint256, List
>>> from eth2spec.utils.merkle_minimal import merkleize_chunks
>>> a = List[uint256, 4](33652, 59750, 92360)
>>> a_len = a.length()
>>> a = List[uint256, 4](33652, 59750, 92360).encode_bytes()
>>> b = List[uint256, 4](33652, 59750, 92360, 0).encode_bytes()
>>> a_root_hash = merkleize_chunks([a[0:32], a[32:64], a[64:96]])
>>> b_root_hash = merkleize_chunks([b[0:32], b[32:64], b[64:96], b[96:128]])
>>> a_mix_len_root_hash = merkleize_chunks([merkleize_chunks([a[0:32], a[32:64], a[64:96]]), a_len.to_bytes(32, 'little')])
>>> print('a_root_hash = ', a_root_hash)
a_root_hash = 0x3effe553b6091b1982a6850fd2a788943363e6f879ff796057503b76802edd9d
>>> print('b_root_hash = ', b_root_hash)
b_root_hash = 0x3effe553b6091b1982a6850fd2a788943363e6f879ff796057503b76802edd9d
>>> print('a_mix_len_root_hash = ', a_mix_len_root_hash)
a_mix_len_root_hash = 0xeca15347139a6ad6e7eabfbcfd3eb3bf463af2a8194c94aef742eadfcc3f1912
>>>
Summaries and Expansions in SSZ Merkleization
In Ethereum PoS, the concepts of summaries and expansions are integral to managing state data efficiently. Summaries provide a compact representation of data structures, encapsulating essential verification information without the full details. Expansions, on the other hand, deliver the complete data set for thorough processing or when detailed information is required. Here are their benefits:
- Efficiency and Speed: By employing summaries, validators can quickly verify state changes or validate transactions without processing entire data sets. This method significantly speeds up validations and reduces computational overhead.
- Reduced Data Load: Summaries minimize the amount of data stored and transmitted, conserving bandwidth and storage resources. This is particularly beneficial for nodes with limited capacity, such as light clients, which rely on summaries for operational efficiency.
- Security Enhancements: The cryptographic hashes included in summaries ensure the integrity of the data, enabling secure and reliable verification processes without accessing the full dataset.
- An Example:
- BeaconBlock and BeaconBlockHeader: The
BeaconBlockHeadercontainer acts as a summary, allowing nodes to quickly verify the integrity of a block without needing the complete block data fromBeaconBlockcontainer.BeaconBlockis the expansion. - Proposer Slashing: Validators use block summaries to efficiently identify and process conflicting block proposals, facilitating swift and accurate slashing decisions.
- BeaconBlock and BeaconBlockHeader: The
Merkleization for Basic Types
Let’s understand the Merkleization of basic types using an example. Below is a simple Merkle tree and we will follow the process of merkleization to get the merkle root hash.
graph TD;
A["A"] --> HAB["H(A + B)"]
B["B"] --> HAB
C["C"] --> HCD["H(C + D)"]
D["D"] --> HCD
HAB --> HROOT["Root: H(H(A+B) + H(C+D))"]
HCD --> HROOT
Figure: Sample Merkle Tree.
In the above Merkle tree, the leaves of the tree are the four blobs of data, A, B, C, and D.
- Define the Data:
- In this example, we’re dealing with four basic data items: A, B, C, and D. These are conceptualized as numbers (
10,20,30, and40respectively) and will be represented in the Merkle tree as 32-byte chunks.
- In this example, we’re dealing with four basic data items: A, B, C, and D. These are conceptualized as numbers (
- Convert Data to 32-byte Chunks:
- Each data item is serialized into a 32-byte format using the
uint256type from the SSZ typing system. Serialization involves converting the data into a format that is consistent and padded to ensure that each item is 32 bytes long.
- Each data item is serialized into a 32-byte format using the
- Pair and Hash the Leaves:
- Next, pairs of these serialized data chunks are concatenated and hashed.
- Hash the Results to Form the Root:
- Finally, the hashes from the previous step (
abandcd) are concatenated and hashed to form the Merkle root.
- Finally, the hashes from the previous step (
- Output the Merkle Root:
- The Merkle root is then converted to a hexadecimal string to make it readable.
This final Merkle root is a unique representation of the data A, B, C, and D. Any change in the input data would result in a different Merkle root, illustrating the sensitivity of the hash function to the input data. This characteristic is essential for ensuring data integrity in Ethereum.
>>> from eth2spec.utils.ssz.ssz_typing import uint256
>>> from eth2spec.utils.hash_function import hash
>>> a = uint256(10).to_bytes(length = 32, byteorder='little')
>>> b = uint256(20).to_bytes(length = 32, byteorder='little')
>>> c = uint256(30).to_bytes(length = 32, byteorder='little')
>>> d = uint256(40).to_bytes(length = 32, byteorder='little')
>>> ab = hash(a + b)
>>> cd = hash(c + d)
>>> abcd = hash(ab + cd)
>>> abcd.hex()
'1e3bd033dcaa8b7e8fa116cdd0469615b29b09642ed1cb5b4a8ea949fc7eee03'
Merkleization for Composite Types
In this section we learn how the IndexedAttestation composite type is Merkleized, using a detailed example to illustrate the process. This example provides clear instances of the Merkleization process applied to composite, list, and vector types. It also showcases how summaries and expansions are effectively demonstrated through this process.
Definition and Structure
The IndexedAttestation is a composite type defined as follows:
class IndexedAttestation(Container):
attesting_indices: List[ValidatorIndex, MAX_VALIDATORS_PER_COMMITTEE]
data: AttestationData
signature: BLSSignature
IndexedAttestation is composed of three primary components:
- attesting_indices: A list of
ValidatorIndex, representing the validators who are attesting. - data: An
AttestationDatacontainer, holding various pieces of data pertinent to the attestation. - signature: A
BLSSignature, which is a signature over the attestation.
Merkleization Process
The Merkleization of IndexedAttestation involves computing the hash tree root of each component and combining these roots to form the overall hash tree root of the container.
Merkleizing attesting_indices:
- Serialization and Padding: First, the list of indices is serialized. Given the potential length of this list (up to the
MAX_VALIDATORS_PER_COMMITTEE), it often requires padding to align with the 32-byte chunks required for hashing. - Hashing: The serialized data is hashed using the
merkleize_chunksfunction, which handles the padding and constructs a multi-layer Merkle tree. - Mixing in Length: Since lists in SSZ can vary in length but have the same type structure, the length of the list is also hashed (mixed in) to ensure unique hash representations for different-sized lists.
attesting_indices_root = merkleize_chunks(
[
merkleize_chunks([a.attesting_indices.encode_bytes() + bytearray(8)], 512),
a.attesting_indices.length().to_bytes(32, 'little')
])
Merkleizing data (AttestationData):
- Handling Nested Structures:
AttestationDataitself contains multiple fields (likeslot,index,beacon_block_root,source, andtarget), each of which is individually serialized and Merkleized. - Combining Hashes: The hashes of these fields are then combined to produce the root hash of the
AttestationData.
data_root = merkleize_chunks(
[
a.data.slot.to_bytes(32, 'little'),
a.data.index.to_bytes(32, 'little'),
a.data.beacon_block_root,
merkleize_chunks([a.data.source.epoch.to_bytes(32, 'little'), a.data.source.root]),
merkleize_chunks([a.data.target.epoch.to_bytes(32, 'little'), a.data.target.root]),
])
Merkleizing signature:
- Simple Hashing: The
BLSSignatureis a fixed-length field and is directly hashed into three 32-byte chunks, which are then Merkleized to get the signature’s root.
signature_root = merkleize_chunks([a.signature[0:32], a.signature[32:64], a.signature[64:96]])
Combining Component Roots:
- The roots calculated from each component are then combined to compute the hash tree root of the entire
IndexedAttestationcontainer.indexed_attestation_root = merkleize_chunks([attesting_indices_root, data_root, signature_root])
Verification of Final Root:
- The correct implementation of Merkleization of
IndexedAttestationensures that changes in any part of the data structure are reflected in the final root hash, providing a robust mechanism for detecting discrepancies and ensuring data consistency across all nodes in the network.
assert a.hash_tree_root() == indexed_attestation_root
Now, you can visualize the full picture of the merkleization of IndexedAttestation:
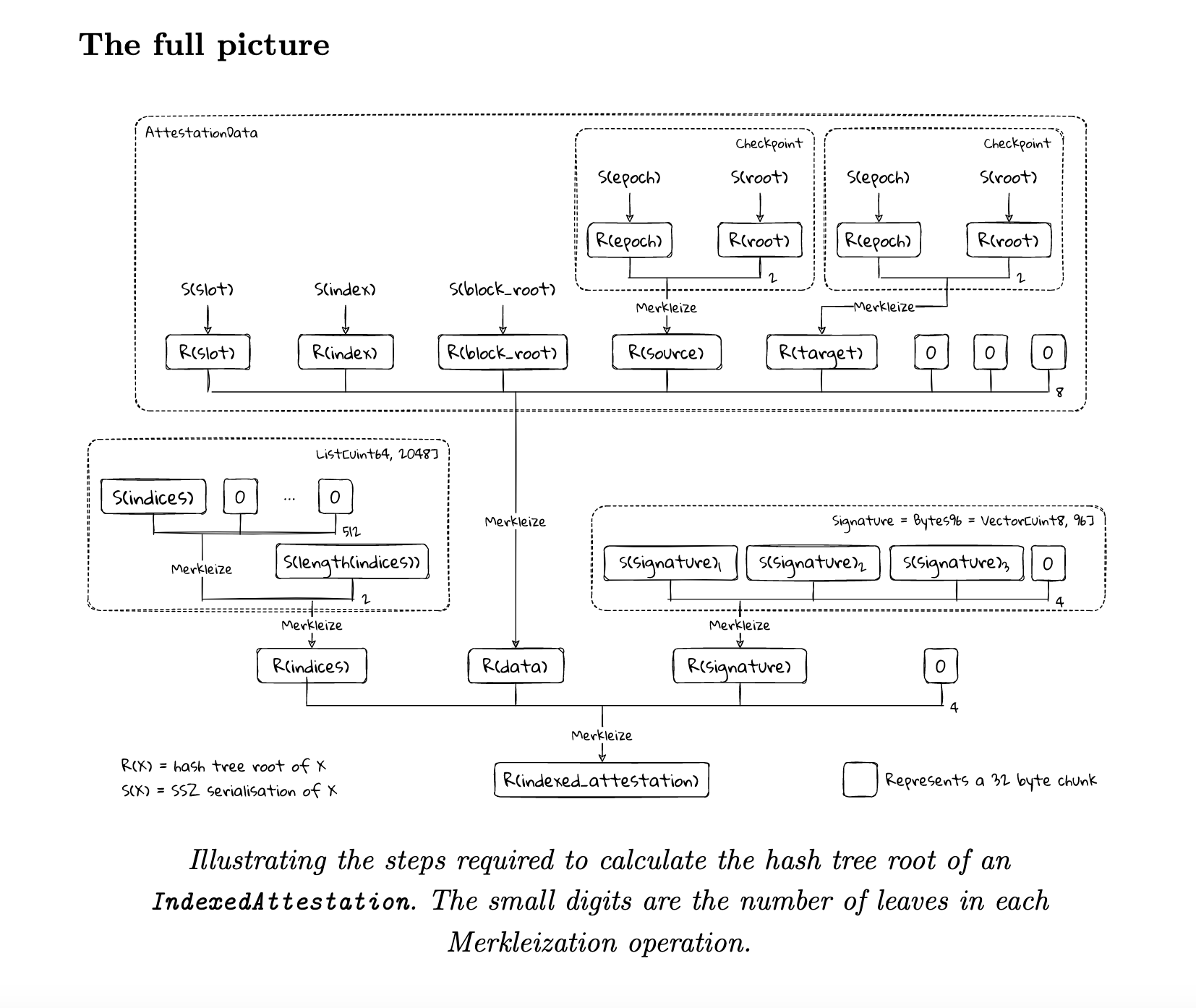
Here is the full working code:
from eth2spec.capella import mainnet
from eth2spec.capella.mainnet import *
from eth2spec.utils.ssz.ssz_typing import *
from eth2spec.utils.merkle_minimal import merkleize_chunks
# Initialise an IndexedAttestation type
a = IndexedAttestation(
attesting_indices = [33652, 59750, 92360],
data = AttestationData(
slot = 3080829,
index = 9,
beacon_block_root = '0x4f4250c05956f5c2b87129cf7372f14dd576fc152543bf7042e963196b843fe6',
source = Checkpoint (
epoch = 96274,
root = '0xd24639f2e661bc1adcbe7157280776cf76670fff0fee0691f146ab827f4f1ade'
),
target = Checkpoint(
epoch = 96275,
root = '0x9bcd31881817ddeab686f878c8619d664e8bfa4f8948707cba5bc25c8d74915d'
)
),
signature = '0xaaf504503ff15ae86723c906b4b6bac91ad728e4431aea3be2e8e3acc888d8af'
+ '5dffbbcf53b234ea8e3fde67fbb09120027335ec63cf23f0213cc439e8d1b856'
+ 'c2ddfc1a78ed3326fb9b4fe333af4ad3702159dbf9caeb1a4633b752991ac437'
)
# A container's root is the merkleization of the roots of its fields.
# This is IndexedAttestation.
assert(a.hash_tree_root() == merkleize_chunks(
[
a.attesting_indices.hash_tree_root(),
a.data.hash_tree_root(),
a.signature.hash_tree_root()
]))
# A list is serialised then (virtually) padded to its full number of chunks before Merkleization.
# Finally its actual length is mixed in via a further hash/merkleization.
assert(a.attesting_indices.hash_tree_root() ==
merkleize_chunks(
[
merkleize_chunks([a.attesting_indices.encode_bytes() + bytearray(8)], 512),
a.attesting_indices.length().to_bytes(32, 'little')
]))
# A container's root is the merkleization of the roots of its fields.
# This is AttestationData.
assert(a.data.hash_tree_root() == merkleize_chunks(
[
a.data.slot.hash_tree_root(),
a.data.index.hash_tree_root(),
a.data.beacon_block_root.hash_tree_root(),
a.data.source.hash_tree_root(),
a.data.target.hash_tree_root()
]))
# Expanding the above AttestationData roots by "manually" calculating the roots of its fields.
assert(a.data.hash_tree_root() == merkleize_chunks(
[
a.data.slot.to_bytes(32, 'little'),
a.data.index.to_bytes(32, 'little'),
a.data.beacon_block_root,
merkleize_chunks([a.data.source.epoch.to_bytes(32, 'little'), a.data.source.root]),
merkleize_chunks([a.data.target.epoch.to_bytes(32, 'little'), a.data.target.root]),
]))
# The Signature type has a simple Merkleization.
assert(a.signature.hash_tree_root() ==
merkleize_chunks([a.signature[0:32], a.signature[32:64], a.signature[64:96]]))
# Putting everything together, we have a "by-hand" Merkleization of the IndexedAttestation.
assert(a.hash_tree_root() == merkleize_chunks(
[
# a.attesting_indices.hash_tree_root()
merkleize_chunks(
[
merkleize_chunks([a.attesting_indices.encode_bytes() + bytearray(8)], 512),
a.attesting_indices.length().to_bytes(32, 'little')
]),
# a.data.hash_tree_root()
merkleize_chunks(
[
a.data.slot.to_bytes(32, 'little'),
a.data.index.to_bytes(32, 'little'),
a.data.beacon_block_root,
merkleize_chunks([a.data.source.epoch.to_bytes(32, 'little'), a.data.source.root]),
merkleize_chunks([a.data.target.epoch.to_bytes(32, 'little'), a.data.target.root]),
]),
# a.signature.hash_tree_root()
merkleize_chunks([a.signature[0:32], a.signature[32:64], a.signature[64:96]])
]))
print("Success!")
You can follow the instructions at running the specs to execute the above code.